EMK - Cluster worker pools
Estimated time to read: 3 minutes
This page describes how to set up worker pools for your Kubernetes cluster. It will also describe how those settings are configured in the YAML structure.
Worker pools allow us to configure the settings for the nodes in a cluster. For example, it is possible to configure different flavor types, Kubernetes version, labels, taints, availability zones and more.
Rolling update triggers
Making changes on a worker group can trigger a rolling update. This will result in draining and evicting nodes to new nodes.
The following configuration changes will definitly trigger a rolling update:
.spec.provider.workers[].machine.image.name.spec.provider.workers[].machine.image.version.spec.provider.workers[].machine.type.spec.provider.workers[].volume.type.spec.provider.workers[].volume.size.spec.provider.workers[].providerConfig.spec.provider.workers[].cri.name.spec.provider.workers[].kubernetes.version(except for patch version changes)
Making changes to worker groups on an EMK Cluster is straightforward.
Navigate to the EMK Cluster overview in the Fuga dashboard
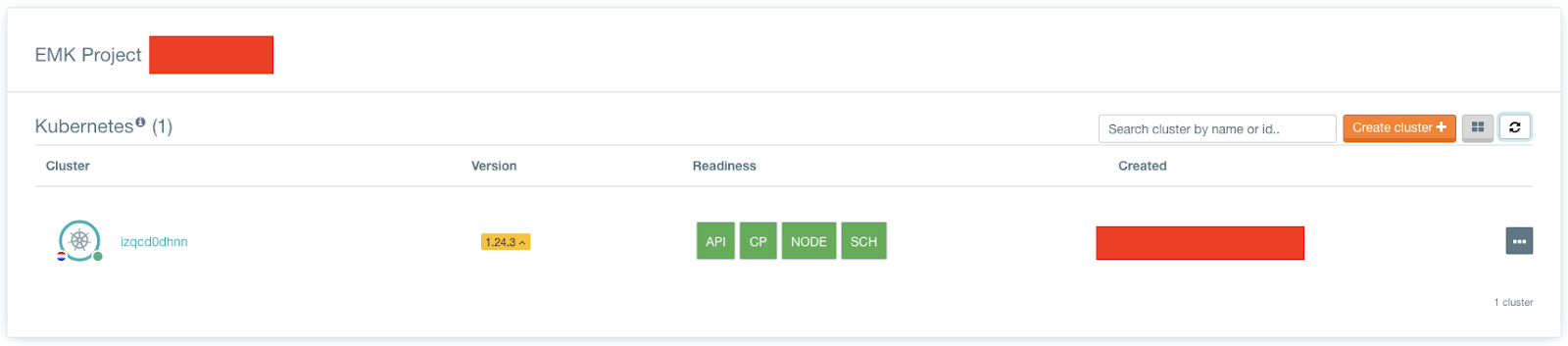
Click on the cluster you want to edit the worker groups and head over to the Workers tab.
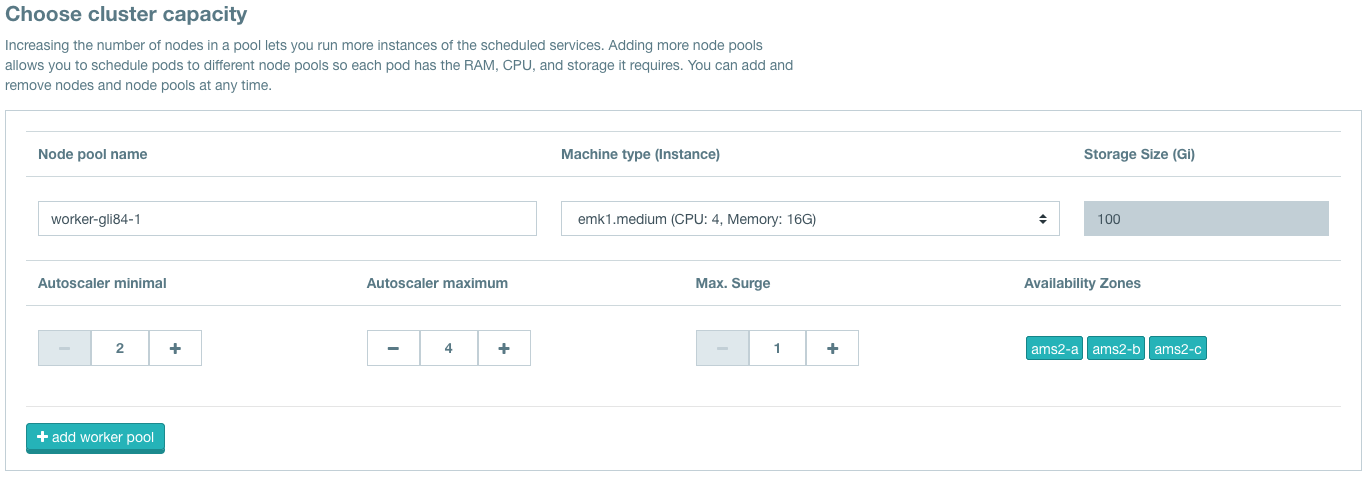
Now you can add more worker pools or change the current ones.
The basic configuration for a worker pool looks like this:
spec:
provider:
workers:
- cri:
name: containerd
name: worker-pool-1
machine:
type: emk1.small
image:
name: gardenlinux
version: 1312.3.0
architecture: amd64
maximum: 4
minimum: 2
maxSurge: 1
maxUnavailable: 0
zones:
- fra-a
- fra-b
- fra-c
systemComponents:
allow: true
It is possible to add more options to a worker pool:
- Labels
- Taints
- Kubernetes version
- Machine controller manager settings
- Cluster autoscaler settings
Labels
Before using labels check if your label is allowed by the node restrictions.
Taints
Kubernetes version
Restrictions:
- Adding another Kubernetes version is not possible if the worker pool is already created.
- It must be at most two minor versions lower than the control plane version.
- If it was not specified before, then no downgrade is possible (you cannot set it to
1.26.8while.spec.kubernetes.versionis already1.27.4). The “two minor version skew” is only possible if the worker pool version is set to the control plane version and then the control plane was updated gradually by two minor versions. - If the version is removed from the worker pool, only one minor version difference is allowed to the control plane (you cannot upgrade a pool from version
1.25.0to1.27.0in one go).
spec:
kubernetes
version: 1.27.4
provider:
workers:
- name: worker-pool-1
kubernetes:
version: 1.26.8
Machine controller manager settings
The .spec.provider.workers[] list exposes two fields that you might configure based on your workload's needs: maxSurge and maxUnavailable. The same concepts like in Kubernetes apply. Additionally, you might customize how the machine-controller-manager (abbrev.: MCM; the component instrumenting this rolling update) is behaving. You can configure the following fields in .spec.provider.worker[].machineControllerManager:
machineDrainTimeout: Timeout (in duration) used while draining of machine before deletion, beyond which MCM forcefully deletes the machine (default:10m).machineHealthTimeout: Timeout (in duration) used while re-joining (in case of temporary health issues) of a machine before it is declared as failed (default:10m).machineCreationTimeout: Timeout (in duration) used while joining (during creation) of a machine before it is declared as failed (default:10m).maxEvictRetries: Maximum number of times evicts would be attempted on a pod before it is forcibly deleted during the draining of a machine (default:10).nodeConditions: List of case-sensitive node-conditions which will change a machine to aFailedstate after themachineHealthTimeoutduration. It may further be replaced with a new machine if the machine is backed by a machine-set object (defaults:KernelDeadlock,ReadonlyFilesystem,DiskPressure).
spec:
provider:
workers:
- name: worker-pool-1
machineControllerManager:
drainTimeout: 10m
healthTimeout: 10m
creationTimeout: 10m
maxEvictRetries: 30
nodeConditions:
- ReadonlyFilesystem
- DiskPressure
- KernelDeadlock